在使用者模式應用程式與加速器之間高效協調,將資料處理最佳化的方案。
簡介
資料導向運算正在蓬勃發展,加速資料中心工作負載及降低 COGS(銷貨成本)越來越受重視。這類加速的硬體方法包括 CPU 核心中的專門指令集架構(ISA)擴充、可程式化的異質元素(例如 GPU 與 FPGA),以及提供資料移動與轉換功能的卸載加速引擎。雖然採用 ISA 的加速在主機 CPU 的指令集架構內有妥善的定義,但卸載型加速從傳統 I/O 控制器與裝置驅動程式模型自然而然演進而來,缺乏一致的架構與功能。這份報告概述即將推出的 Intel® Xeon® 處理器,採用的各種加速器介面技術。這類技術旨在降低卸載例行成本、儘量減少端對端延遲、簡化記憶體模型,以及針對透過虛擬機器和/或容器部署的工作負載,提供合適的可擴充虛擬化功能。
現況
從傳統 I/O 控制器設計演進而來的卸載加速硬體與軟體,面臨種種難題。這些難題包括工作提交例行成本、記憶體管理複雜度、工作完成同步例行成本,以及應用程式或租用戶共用加速器。
工作提交例行成本
傳統上,應用程式向加速器提交工作時,要求會傳送至核心模式裝置驅動程式,將基礎加速器裝置軟硬體之間的介面抽象化。與核心 I/O 堆疊相關的延遲與例行成本,可能對高效能串流加速器造成瓶頸。
記憶體管理複雜度例行成本
傳統加速器設計需要鎖定記憶體,才能在應用程式與硬體加速器之間共享資料。此外,從加速器角度看待記憶體(透過直接記憶體存取的方式存取)以及從應用程式角度看待記憶體截然不同,通常需要基礎軟體堆疊,透過昂貴的記憶體鎖定與解除鎖定,以及 DMA 對應與取消對應作業,才能協調這兩個觀點取得共識。
工作完成同步例行成本
加速器現有的軟體堆疊仰賴中斷式驅動的處理方式、忙碌輪詢完成狀態暫存器,或是記憶體中的描述元。作業系統核心中的中斷式處理架構,進行上下文切換與延遲處理時會產生例行成本,進而降低系統效能。另一方面,忙碌輪詢功耗更高,造成其他應用程式可用的 CPU 週期數減少,而且可能對擴充產生負面影響。
加速器共享性
在多個並行應用程式、容器與虛擬機器之間高效安全共用加速器,是部署資料中心的基本要求。硬體輔助式 I/O 虛擬化,例如 SR-IOV,根據客體軟體需求,從存取加速器過程將 Hypervisor 排除,加速 I/O 虛擬化。
然而,這類架構往往屬於硬體密集型,比較不適合兩種設計:
- 資源受限的系統單晶片(SoC)整合式加速器設計
- 使用案例需要的擴充性,比虛擬機器型應用目前提供的擴充性還高(例如,在數千個並行容器之間共用一個加速器的使用情況)
總之,加速器的系統架構必須滿足以下需求:
- 卸載效率——低例行成本、使用者模式、功能卸載(可擴充與低延遲工作分派、輕量級同步、事件訊號發送等)
- 記憶體模型——從卸載至加速器之應用程式與功能的角度統一看待記憶體
- 虛擬化——在應用程式、容器與虛擬機器之間高效共用加速器
- 一致性——所有 IP 的軟硬體介面與 SoC 介面架構一致
加速器介面技術
本節概述即將推出之 Intel® Xeon® 處理器的加速器介面技術功能。
這些功能除滿足上述要求,還兼顧以下幾個層面:
- 可最佳化卸載的工作分派指令(MOVDIRI、MOVDIR64B、ENQCMD/S)
- 可高效同步的使用者模式等待指令(UMONITOR、UMWAIT、TPAUSE)
- 低延遲使用者中斷
- 共享虛擬記憶體
- 可擴充 I/O 虛擬化
加強卸載效率與可擴充性
MOVDIRI
使用直接儲存語意實現高處理量(4B 或 8B)門鈴寫入,嘉惠串流卸載模型,將小型工作單位高速串流至加速器。
MOVDIR64B
實現對加速器工作佇列的 64 位元原子寫入,幫助低延遲卸載模型實現效益,讓模型中的加速器裝置高度最佳化,以最少的延遲完成要求的作業。64 位元承載讓加速器得以在擷取工作描述元時避免 DMA 讀取延遲,而且在某些情況下,即使是擷取實際資料也可避免延遲(進而減少端對端延遲)。
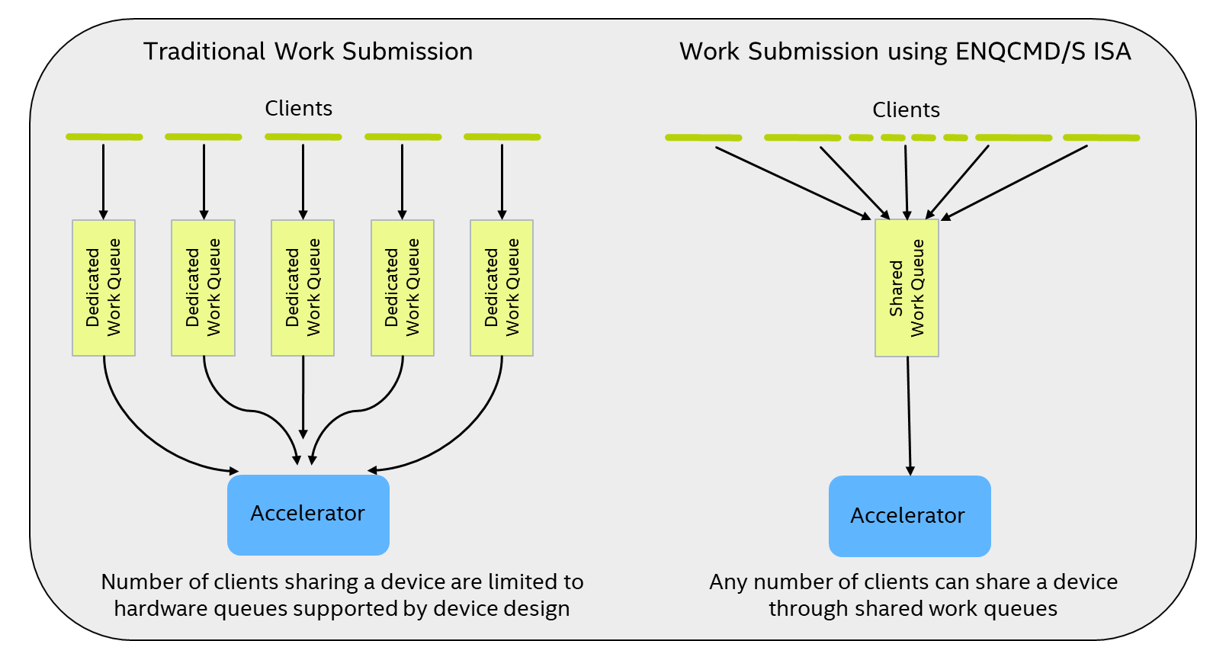
ENQCMD/S
支援將多重非合作軟體實體(例如 VM 內部的應用程式、容器或應用程式/容器)的工作同步直接提交至加速器的工作佇列(稱為共用工作佇列或 SWQ),如下圖所示。將 ENQCMD(將指令加入佇列)與 ENQCMDS(將指令當成主管加入佇列)指令加入佇列的指令,有兩項獨特的特點:
- 工作描述元內有一個處理序位址空間識別碼(PASID),可讓加速器根據每個描述元識別提交軟體代理程式
- 這些指令使用 PCIe* 可延遲記憶體寫入(DMWr)要求,讓加速器得以執行或延遲傳入的 DMWr 要求
ENQCMD/S 指令向軟體回傳「成功」或「重試」(延遲)指示。成功代表工作被 SWQ 接受,而重試則表示,由於 SWQ 容量、QoS 或其他原因,工作未被接受。工作提交者收到重試狀態時,可以稍後重試。
UMONITOR/UMWAIT/TPAUSE
在使用者模式軟體與卸載任務之間實現低延遲同步。此外,處理器得以進入依實作有所不同的最佳化狀態,同時等候加速器完成已派遣的工作。最佳化狀態可能是輕量型功耗或效能最佳化狀態,或是增強型功耗/效能最佳化狀態。UMWAIT 與 TPAUSE 指令可讓軟體從這兩種最佳化狀態選擇,同時也提供了可指定自選逾時值的機制。TPAUSE 指令可與交易同步延伸模組一起使用,等待多重事件。這些指令讓超執行緒(HT)在同層級執行緒高效等待事件時,利用運算資源。
使用者中斷
實現向使用者模式軟體直接發送訊號的輕量型機制。使用者中斷可在沒有任何核心介入的情況下,將事件交付給使用者空間應用程式,而且可供核心代理程式用於向使用者空間應用程式傳送通知,取代使用作業系統訊號發送機制。使用者中斷可減少高效能應用程式的端對端延遲、整體波動,以及上下文切換的例行成本。
共用虛擬記憶體(SVM)
SVM 架構透過以下方式,讓 CPU 與加速器從統一的角度看待記憶體:
- 讓加速器使用與 CPU 相同的虛擬位址
- 讓加速器存取未鎖定的記憶體,以及從 I/O 頁面錯誤復原
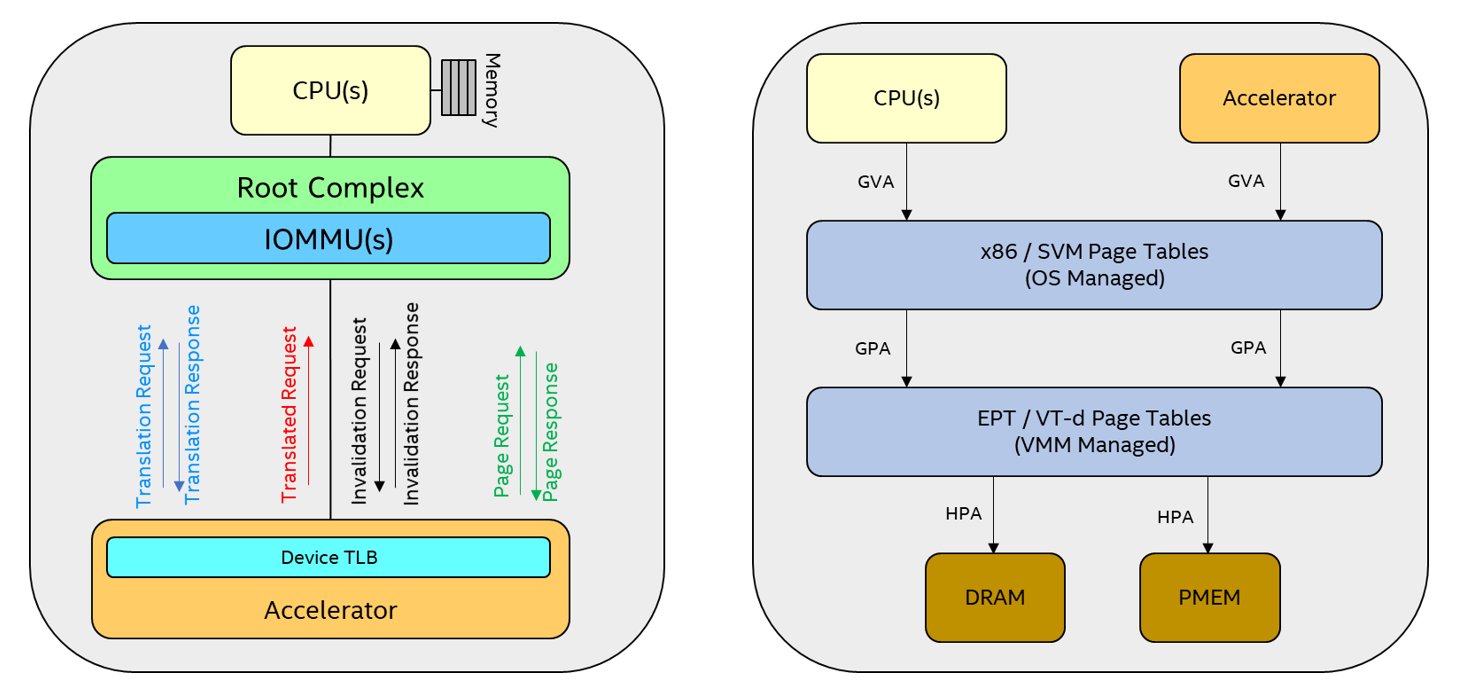
即將推出的 Intel Xeon 處理器支援 SVM 功能,例如處理序位址空間識別碼(PASID)、位址翻譯服務(ATS)以及頁面要求服務(PRS)。系統軟體會分配 PASID,識別提交工作之每個用戶端的位址空間,而且 Intel® 虛擬化技術會延伸,以此共用用戶端的 CPU 分頁表,執行 PASID 精細 DMA 重新對應,並且協助加速器從 I/O 頁面錯誤復原。
加速器使用 SVM 功能,直接處理應用程式位址空間的資料。加速器收到工作描述元時,會查找 DMA 位址轉譯的裝置轉換後備緩衝區(DevTLB);如果位址轉譯已快取(DevTLB 命中的情境),則會發出 DMA 要求以及自 DevTLB 獲得的轉譯後主機實體位址(HPA)。若是 DevTLB 未命中,則加速器會向 IOMMU 發出 ATS 位址轉譯要求,由 IOMMU 參考位址轉譯表,取得轉譯結果。轉譯成功時,DevTLB 會快取回傳的位址轉譯資訊,並且發出 DMA 要求。轉譯失敗時(亦即 I/O 頁面錯誤),加速器可向系統軟體發出 PRS 頁面要求,為錯誤頁面發出「頁面載入」要求(例如 CPU 頁面錯誤處理)。加速器收到成功的頁面回應時,會在主機成功處理錯誤後重新發出位址轉譯要求,取得轉譯結果。
系統軟體修剪處理序的工作集、處理對 VMM 記憶體的過度使用,以及終止應用程式或 VM 等,可能變更應用程式/VM 分頁表。如果發生這種情況,系統軟體會指示加速器,將與此變更相關的 DevTLB 條目作廢,然後同步處理回應。
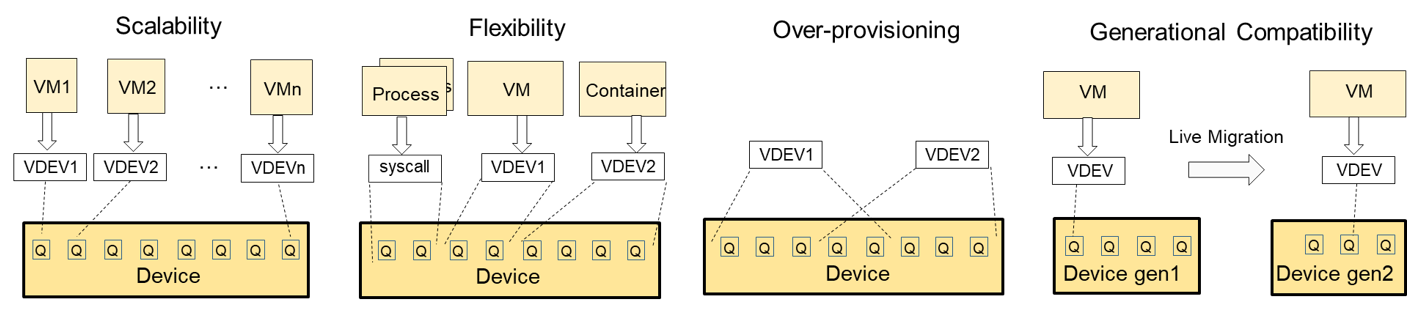
Intel® Scalable I/O Virtualization (Intel® Scalable IOV)
Intel Scalable IOV 是硬體輔助 I/O 虛擬化的新方法。這個方法可在獨立網域(應用程式、VM、容器等)以精細、靈活、高效能的方式共用 I/O 裝置,同時為端點硬體裝置減少這類共用的複雜度。此外,還可將精細佈建的裝置資源(例如工作佇列、佇列配對或上下文)獨立指派給用戶端網域。加速器的軟體存取分類屬於「直接路徑」或「攔截路徑」。直接路徑存取(例如工作提交或工作完成處理)直接對應至加速器資源,有助於改善效能。攔截路徑存取類似組態作業,由虛擬裝置組合模組(VDCM)模擬,有助於提高彈性。此外,Intel Scalable IOV 延伸 Intel® VT-d,支援 PASID 精細 DMA 重新對應,讓指派至不同網域的裝置資源享有精細的隔離。
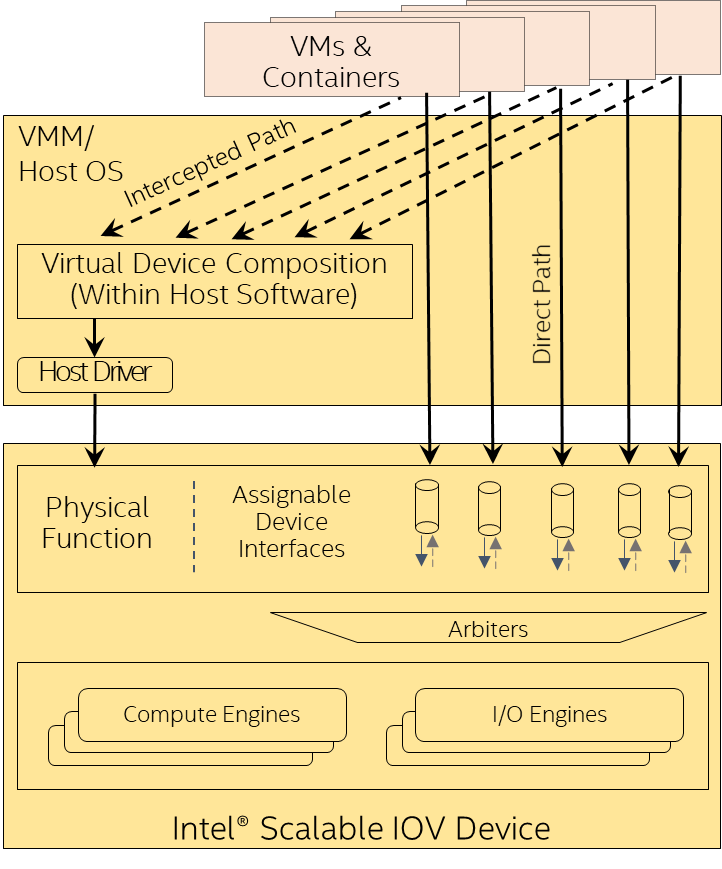
Intel Scalable IOV 為位址網域不同且使用不同抽象層(例如系統呼叫 VM 的應用程式處理序或虛擬裝置介面)的裝置資源,提供彈性的共用方式。還可將 VDEV 動態對應至裝置資源,讓 VMM 得以過度佈建裝置資源。更廣泛而言,儘管實體 I/O 裝置屬於不同世代,但 Intel Scalable IOV 使用 VDCM 將 VDEV 功能虛擬化,並提供相容的 VDEV 功能,讓 VMM 得以維持資料中心的世代相容性。這樣一來,便可確保有 VDEV 驅動程式的特定客體作業系統映像,可部署或移轉至任何實體機器。
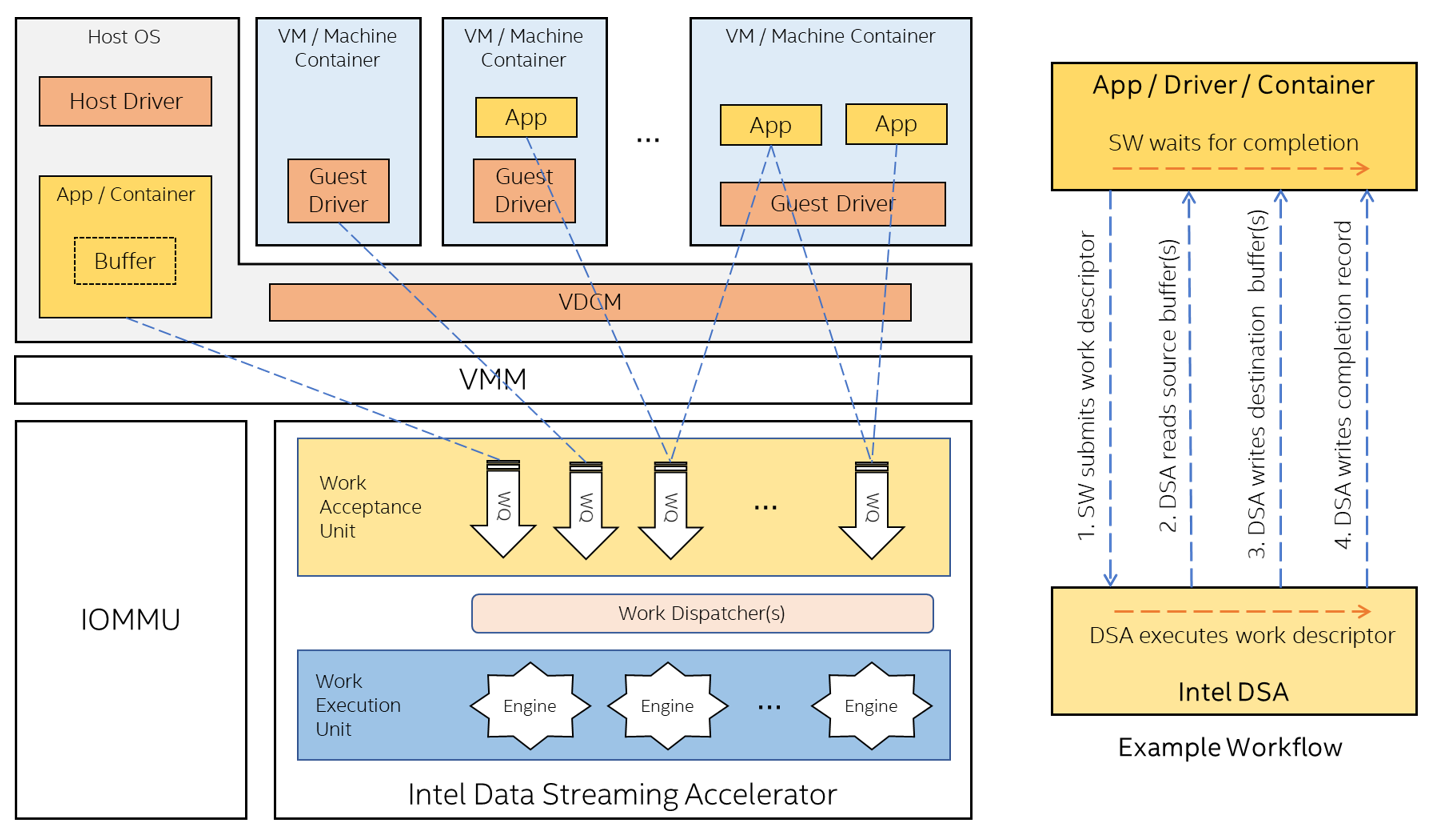
採用 Intel® Data Streaming Accelerator 的加速器介面技術
Intel® Data Streaming Accelerator (Intel® DSA) 是複製與轉換資料的高效能加速器,已整合至即將推出的 Intel Xeon 處理器。 Intel DSA 旨在將串流資料的移動與轉換最佳化。對於專為高效能儲存裝置、網路、持續性記憶體,以及各種資料處理應用所設計的應用程式,這種最佳化稀鬆平常。
Intel DSA 運用先前所說的加速器介面技術,實現高效可擴充的加速器卸載,同時降低建置這種可擴充加速器硬體的相關成本,並且化繁為簡。
Intel DSA 支援裝置託管的專用工作佇列(DWQ),讓個用戶端得以擁有或控制工作佇列的流量/佔有率,以及裝置託管的共用工作佇列(SWQ),進而實現可擴充的共用方式。如下圖所示,軟體可能將 DWQ 指派給單一個別用戶端,同時將 SWQ 對應至一個或多個用戶端。軟體使用 MOVDIR64B 指令,將 64 位元工作描述元提交至 DWQ,並且使用 ENQCMD/S 指令,將 64 位元工作描述元提交至 SWQ。工作描述元還可以要求完成中斷、完成寫入,或同時要求兩者,透過 UMONITOR/UMWAIT 指令實現高效同步處理。
Intel DSA 支援 SVM 與可復原 I/O 頁面錯誤,實現簡化的程式設計模型,並且讓應用程式、作業系統與 Hypervisor 軟體採用這款模型時順暢無礙。為可擴充 I/O 虛擬化功能提供支援,實現了虛擬機器或容器型部署的 Intel DSA 卸載,並且在 Intel DSA 虛擬裝置持續指派給 VM 或容器的同時,使即時移轉成為可行的作法。